Circuit Breaker pattern
Circuit Breaker pattern
![]()
Сегодня хочу рассмотреть такие понятия, как микросервисы, возможные стратегии обработки и остановиться на паттерне Circuit Breaker.
Наверняка многие слышали (уже работали) с микросервисной архитектурой построения приложений.
Не буду углубляться в детали, но если в двух словах:
Архитектура построения приложений строится на двух принципах: монолит и микросервисы. У каждого подхода есть свои плюсы и минусы.
Микросервисная архитектура — это подход, при котором единое приложение строится как набор небольших сервисов, каждый из которых работает в собственном процессе и коммуницирует с остальными.
Другими словами это воплощение паттернов High Cohesion и Low Coupling. Так что микросервис обязан быть независимым компонентом.
Допустим у нас есть некоторое приложение, которое содержит множество микросервисов. Все они общаются между собой, один из них получает данные из базы, передает другому, тот в свою очередь обрабатывает их, передает полученный id следующему сервису и так далее по цепочке.
Если в нашем приложении в каком-либо блоке произошла какая-либо ошибка (или БД), один из сервисов, который передает результат по цепочке через другие сервисы отвалился и все стало очень плохо.
Хочу рассказать про несколько возможных стратегий обработки ошибок.
- Параллельная отправка запросов
Рассмотрим ситуацию с двумя сервисами (если принцип будет понятен, то его можно использовать в среде, где содержится большее количество сервисов)
У нас есть сервис А и сервис B. Сервис А передает данные сервису B, который в свою очередь записывает эти данные в БД, а какой-то другой сервис получает эти данные и передает дальше.
Мы можем параллельно отправлять запросы, если наш сервис B имеет реплику. Даже если один пройдет не успешно, а второй успешно, мы будем счастливы.

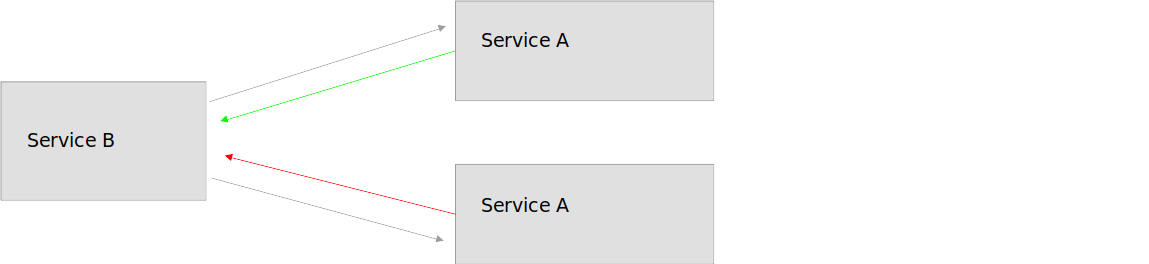
Но давайте представим такую ситуацию, когда оба запроса окажутся успешными, но это может понести какие-либо последствия ?
Например при покупке товара вы пытаетесь оплатить банковской картой. Вы отправили 2 запроса на оплату товара и они оба выполнились успешно. Это не совсем приятно. Но как же быть в такой ситуации ?
Данную проблемы можно попробовать решить при помощи паттерна
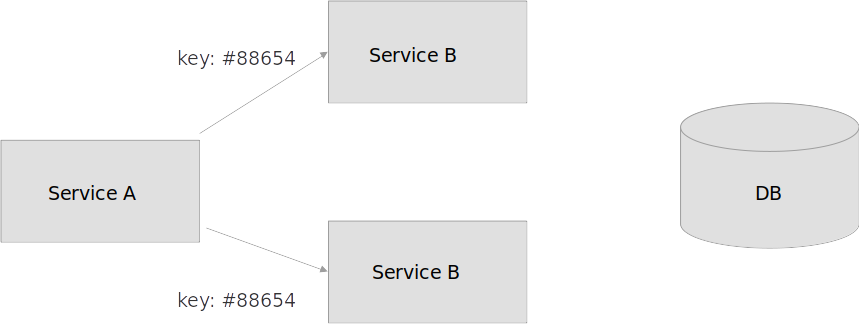
2. Idempotency Key
Каждый наш запрос из сервиса А мы снабжаем ключем, подписываем, говорим сервису B что вот этот запрос наш и у него такой вот идентификатор.

Сервис B перед тем как выполнить запрос складывает его в базу и помечает, что вот этот запрос он сейчас обрабатывает. В итоге 2 одинаковых ключа мы положить не можем в БД => мы можем быть уверены, что наш запрос выполнится единожды.

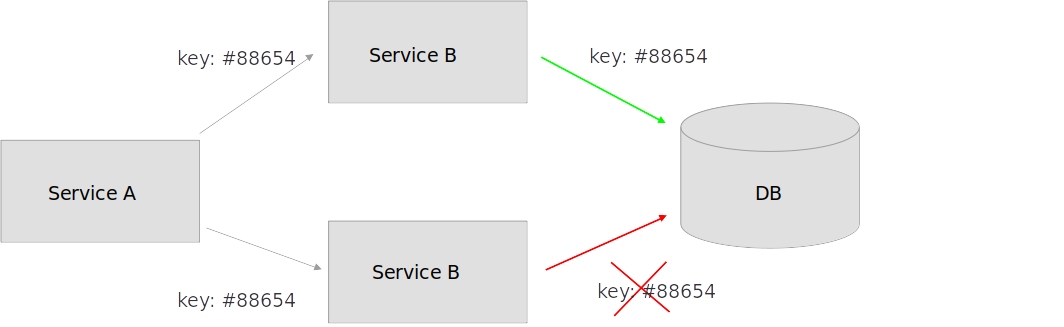
Вроде бы все пока хорошо.
Для параллельной отправки запросов подойдут не все запросы. Мы должны быть уверены, что: + есть несколько реплик сервиса B, + запрос идемпотентен (то свойство, когда мы можем безопасно переотправлять запрос, т.к. мы получим один и тот же результат). Идемпотентными запросами обладают GET, HEAD, PUT, DELETE. + используем Idempotency key, + требуется какая-либо доработка стороннего сервиса, т.к. может оказаться, что сторонний сервис (или БД) и мы никак не можем на него повлиять. В таком случае потребуется что-либо придумать на клиентской стороне, чтобы уведомить пользователя о данной проблеме.
Если рассмотреть пример оплаты товара в интернет магазине банковской картой (мы рассматривали его выше).
3. Переотправка запросов (Retry pattern)
Мы будем переотправлять запрос до тех пор, пока он не окажется успешным.


Сколько же раз стоит повторять ? Перед тем как повторять отправку, можно проверить, что это за ошибка. Если пользователь ввел неверные данные карты, то сколько бы мы не пробовали раз повторить, то все равно не получится совершить удачный запрос. Если исчерпали какое-то кол-во попыток,то не стоит пробовать отправлять дальше до бесконечности. Например такую ошибку можно сразу показать. Если возникла ошибка timeout exception или too many request, тогда можем попытаться отправить снова.
Допустим мы посылаем запросы на сервер и в какой-то момент сервер перестал отвечать на запросы.
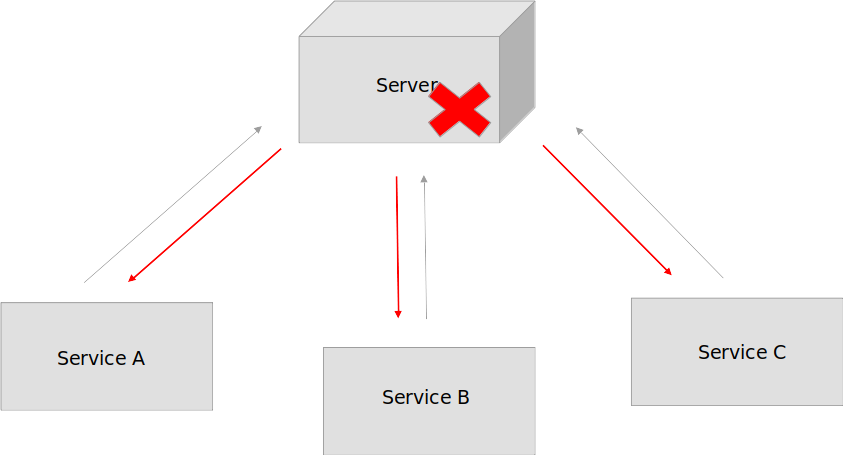
Здесь лучше дать серверу некоторое время чтобы он восстановил свою работу (условно 1–2 секунды или более) и снова повторить запрос.
Стратегии ожидания бывает слудющие:
- без ожидания (no delay), когда сразу без паузы повторяем отправку запроса
- с константным значением (constant), когда устанавливаем строго заданный лимит
- с линейным значением (linear)
- с экспоненциальным значением (exponencial)

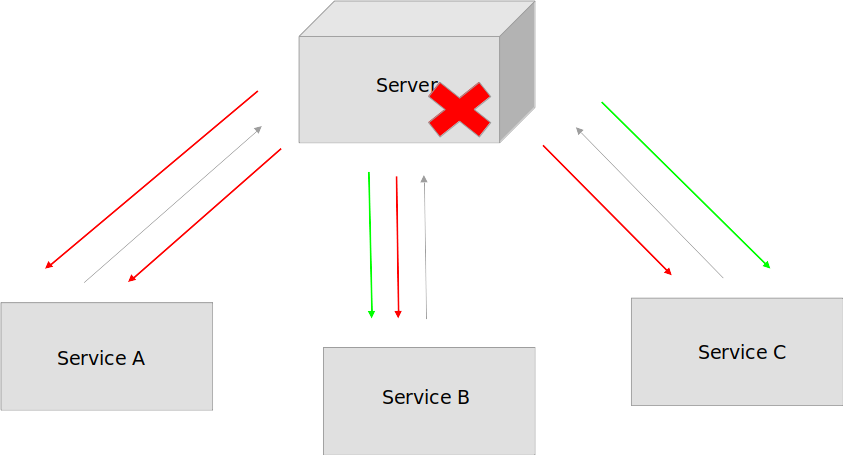
И как мы можем увидеть этого не достаточно
Сервисы ждут какое то время и опять шлют свои запросы. Сервер не в состоянии ответить и отсылает всем ошибку. В таком случае логично добавить какое то время задержки (delay) — случайное смещение (вперед, назад) к этой задержке. Чтобы они не отсылали свои запросы все одновременно. Это будет логичным решением в данной ситуации.
В каких случаях стоит использовать Retry паттерн ?
- Когда в вашем приложении при работе с удаленным сервисом могут возникнуть временные ошибки. Эти ошибки имеют кратковременный характер и высока вероятность того, что следующие запросы будут завершены успешно (Временная недоступность сервиса или тайм-ауты из-за пиковой нагрузки на сервис).
Когда не стоит использовать данный паттерн ?
- Когда ошибки имеют долговременный характер, и приложение будет бесполезно тратить ресурсы на попытки повторить операции (в этом случае стоит задуматься об использовании Circuit Breaker)
- Для обработки ошибок связанных с бизнес-логикой приложения
- Если сервис слишком часто сигнализирует о том, что он “занят”, то скорее всего он требует больше ресурсов
4. Circuit Breaker pattern
В Spring обычно берут реализацию из Netflix стека, которая называется Hystrix.


Hystrix — это библиотека задержек и отказоустойчивости, это имплементация паттерна Circuit Breaker. Как сказано из оффициальной документации: Hystrix — это библиотека, которая помогает вам контролировать взаимодействие между этими распределенными сервисами, добавляя терпимость к задержкам и логику отказоустойчивости.
В отличии от паттерна Retry, паттерн Circuit Breaker рассчитан на менее ожидаемые ошибки, которые могут длиться намного дольше:
- обрыв сети,
- отказ сервиса, оборудования
В этих ситуациях при повторной попытке отправить аналогичный запрос с большой долей вероятности мы получим аналогичную ошибку.
Например, приложение взаимодействует с неким сервисом, и в рамках реализации запросов и ответов предусмотрен некоторый тайм-аут, по истечении которого, если от сервиса не получен ответ, то операция считается не успешной. В случае проблем с этим сервисом, во время ожидания ответа приложение может потреблять какие-то критически важные ресурсы (память, процессорное время), которые скорее всего нужны другим частям приложения. Следовательно, эти ресурсы могут закончиться, что приведет к сбою других, несвязанных частей системы, которым нужно использовать те же ресурсы. В этих ситуациях предпочтительно, чтобы операция немедленно завершалась с ошибкой и не пыталась вызвать службу снова и снова. Кроме того, если служба занята, сбой в одной из частей системы может привести к лавинообразному накоплению сбоев.
Есть готовое решение для подобного рода проблем:
Паттерн Circuit Breaker предотвращает попытки приложения выполнить операцию, которая скорее всего завершится неудачно, что позволяет продолжить работу дальше не тратя важные ресурсы, пока известно, что проблема не устранена. Приложение должно быстро принять сбой операции и обработать его.

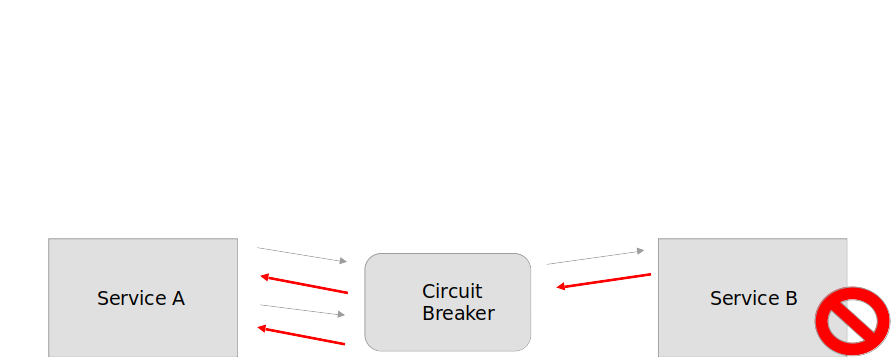
Он также позволяет приложению определять, была ли устранена неисправность. Если проблема устранена, приложение может попытаться вызвать операцию снова.
Circuit Breaker выступает как прокси-сервис между приложением и удаленным сервисом. Прокси-сервис мониторит последние возникшие ошибки, для определения, можно ли выполнить операцию или просто сразу вернуть ошибку.
Если на сервисе B что-то пошло не так, то он возвращает сервису А ошибку и запоминает, что там есть ошибки, и просто последующие запросы не отправит на сервис B. Мы не тратим ресурсы сервера в таком случае.
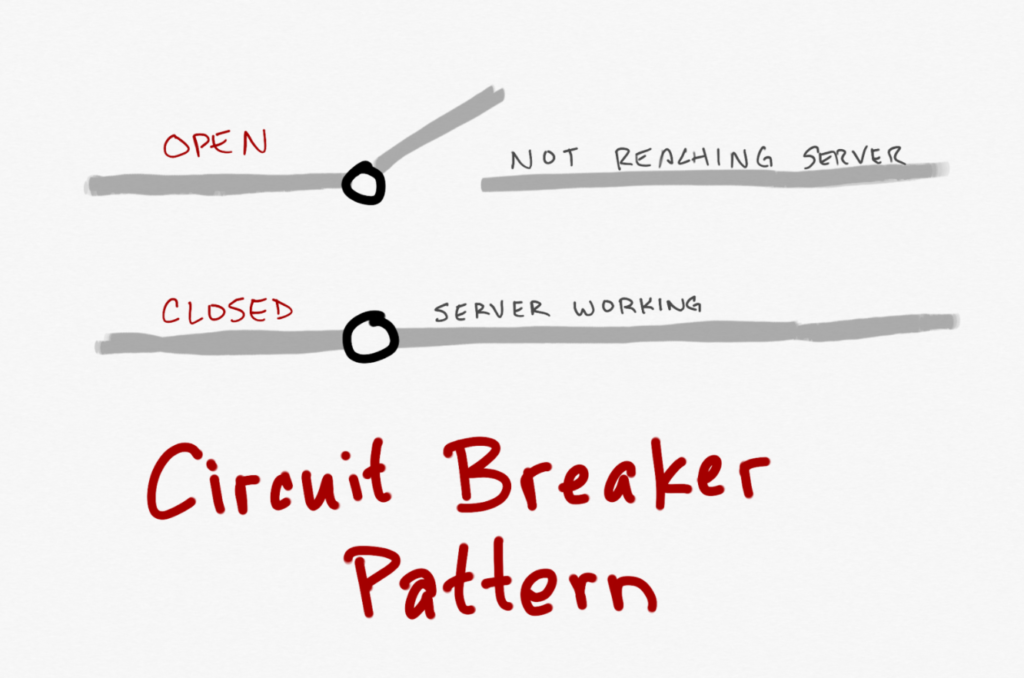
У него есть 3 состояния:
- Closed: запрос от приложения направляется напрямую к сервису. Счетчик ошибок = 0 и приложение спокойно функционирует и шлет запросы направо и налево. Все счастливы.

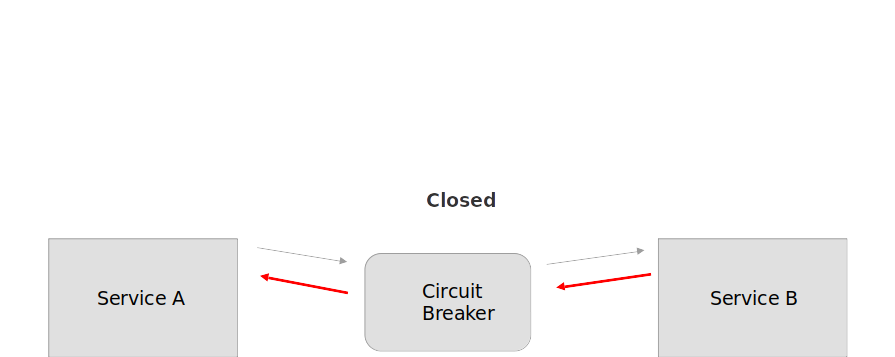
Прокси-сервис увеличивает счетчик ошибок, если операция завершилась неуспешно. Если количество ошибок за некоторый промежуток времени превышает заранее заданный порог значений, то прокси-сервис переходит в состояние Open и запускает таймер времени ожидания. Когда таймер истекает, он переходит в состояние Half-Open. Назначение таймера — дать сервису время для решения проблемы, прежде чем разрешить приложению попытаться выполнить операцию еще раз.
2) Open: запрос от приложения немедленно завершает с ошибкой и исключение возвращается в приложение.

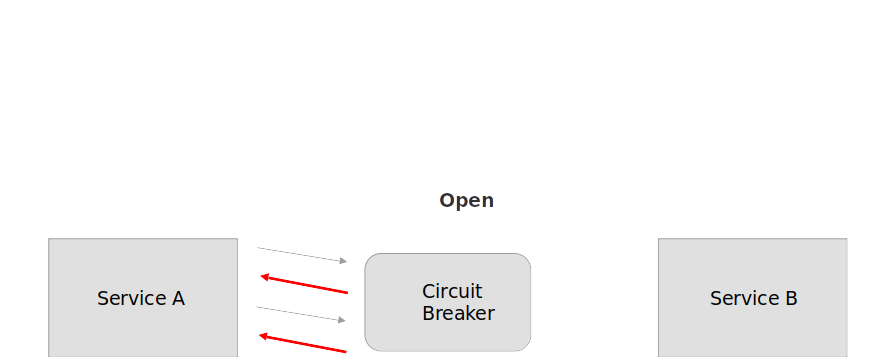
3) Half-Open: ограниченному количеству запросов от приложения разрешено обратиться к сервису. Если эти запросы успешны, то считаем что предыдущая ошибка исправлена и прокси-сервис переходит в состояние Closed (счетчик ошибок сбрасывается на 0). Если любой из запросов завершился ошибкой, то считается, что ошибка все еще присутствует, тогда прокси-сервис возвращается в состояние Open и перезапускает таймер, чтобы дать системе дополнительное время на восстановление после сбоя.
Состояние Half-Open помогает предотвратить быстрый рост запросов к сервису. Т.к. после начала работы сервиса, некоторое время он может быть способен обрабатывать ограниченное число запросов до полного восстановления.
Шаблон Circuit Breaker обеспечивает стабильность, пока система восстанавливается после сбоя и снижает влияние на производительность.
Благодаря этому можно поддерживать определенный показатель времени отклика системы, быстро отклоняя запрос на операцию, которая, скорее всего, завершится со сбоем, вместо того чтобы ждать, пока не истечет время ожидания операции или ждать в течение неопределенного времени (так как операция никогда не возвратится).
Схематично работа паттерна Circuit Breaker выглядит подобным образом.
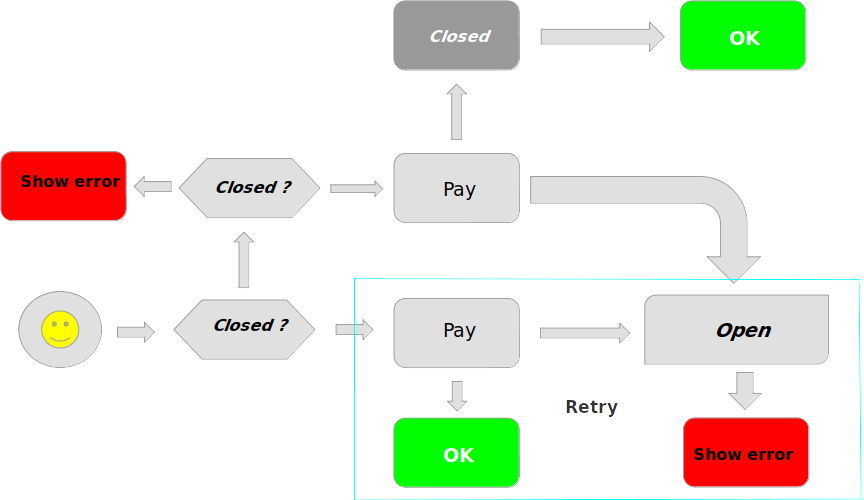
Возьмем пример с оплатой картой:
- проверяем, в каком состоянии circuit breaker
- если закрыт (Closed), то отправляем запрос на сервер, делаем попытку оплаты, все хорошо и все счастливы
- если произошла ошибка, то переводим в состояние Open, запускаем таймер, и показываем ошибку
- следующий раз, когда будем слать запрос, состояние уже не Closed, а Open, то мы проверяем тот самый таймер (таймер — это то время, которое мы даем серверу на восстановление). Если он не истек, т.е. эта условная скажем минута еще не прошла, то мы на клиенте завершаемся с ошибкой, которая была в предыдущем запросе. Если таймер истек — пробуем оплатить, все хорошо — переводим в состояние Closed, выключаем таймер и завершаем оплату заказа. Если все плохо — то возвращаемся на шаг Open.
Эта часть хорошо комбинируется с паттерном Retry, ведь не после каждой ошибки стоит блокировать, например если ошибка кратковременного характера (как уже говорилось ранее), можем попробовать отправить запрос еще раз, несколько попыток и только потом переводить в состояние счетчика.
Какой можем сделать вывод ?
Паттерн Circuit Breaker добавляет стабильности, когда система восстанавливается после падения и минимизирует влияние этого падения на производительность. Можно отслеживать события перехода по статусу для мониторинга и уведомления администраторов о возникшей ошибке.
Когда стоит использовать ?
- Для предотвращения попыток обращения к сервису или разделяемым ресурсам, когда вероятность возникновения ошибки высока и эти ошибки имеют продолжительный характер.
Когда не стоит использовать ?
- Для обращения к приватным ресурсам приложения — это даст только дополнительный overhead
- Как замена обработки исключений бизнес-логики приложения
Надеюсь что смог понятно в кратце изложить суть данного паттерна.
Документации на русском по данной теме практически нет и когда у меня была необходимость разобраться с ним, у меня возникали неоднозначные вопросы по его работе. Скажу, что официальная документация очень скудная.
В следующей теме попробую рассказать про него более подробно на примере реальных сервисов.